[ SITREP ]
- INCIDENT TRIGGER: To democratize access to health screening by providing a non-invasive, AI-powered tool for early diabetes detection. It addresses the “silent epidemic” where individuals remain undiagnosed due to the cost and complexity of clinical screenings.
- OBJECTIVE: Deploy a highly accessible inferencing application capable of evaluating user inputs against a pre-trained clinical model in under 30 seconds.
[ APPLICATION_CONTEXT ]
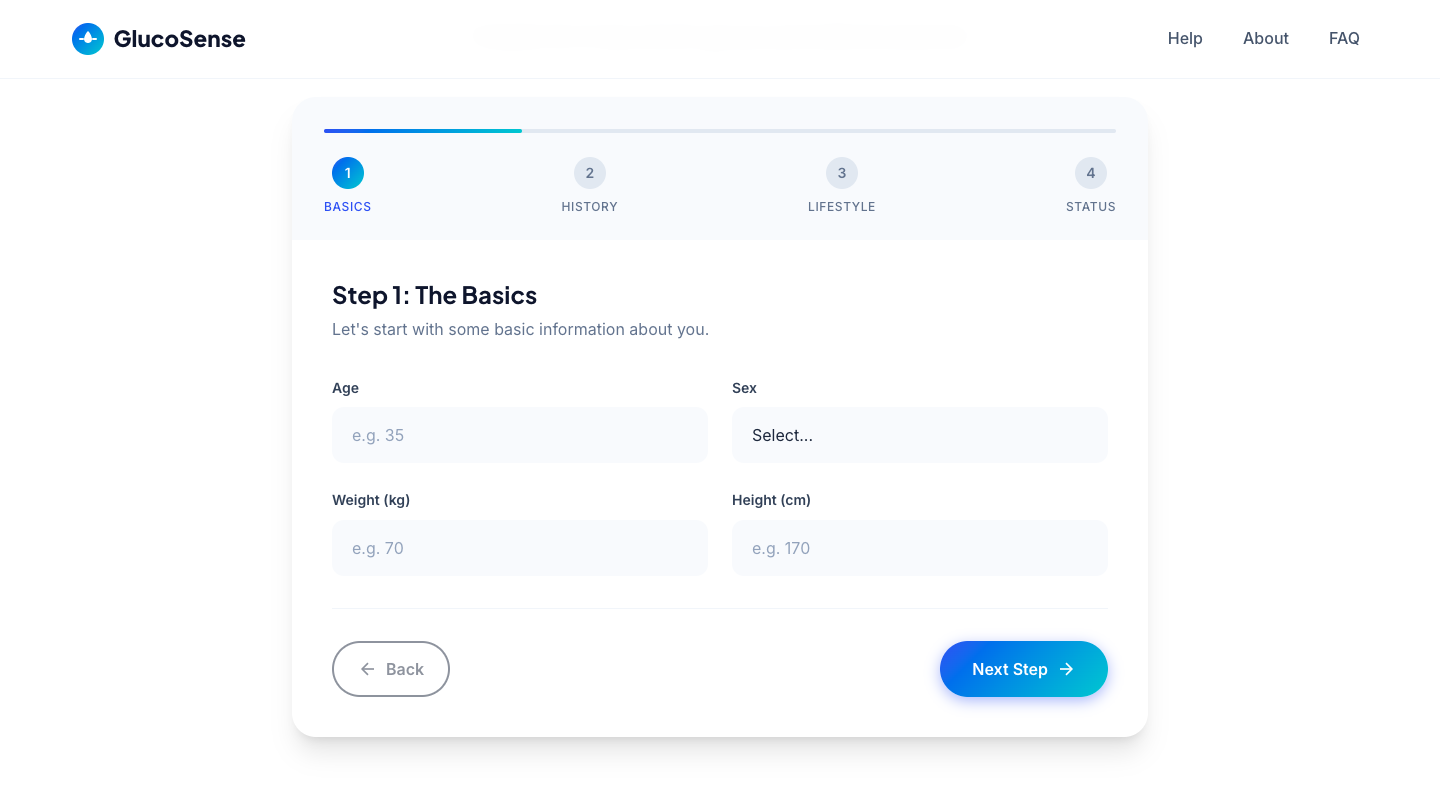
GlucoSense is a responsive, web-based assessment tool. Users navigate a simple 4-step wizard answering non-invasive lifestyle and biometric questions. The system processes these answers through an embedded Machine Learning model to return an immediate diabetes risk categorization.
[ SYSTEM_TOPOLOGY ]
- CLIENT_NODE: HTML5/CSS3 + Vanilla JS (ES6+) with Bootstrap 5.3 strictly managing the 4-step wizard state.
- API_GATEWAY: Python 3.9+ Flask backend utilizing Marshmallow for strict input validation and schema enforcement.
- ML_INFERENCE_ENGINE: Scikit-Learn Random Forest Classifier (Trained on 70,000+ records from CDC BRFSS 2015), serialized via Joblib.
- INFRA_LAYER: Render (API execution) and Static Hosting (Frontend delivery).
[ FAILURE_ANALYSIS // DIMENSIONALITY_MISMATCH ]
- DETECTED_ANOMALY: Model inference failed continuously during real-world user testing.
- ROOT_CAUSE: The underlying BRFSS model requires exactly 21 clinical/socio-economic features (many categorical). To meet the “under 30-second assessment” goal, the user UI was restricted to 17 simple questions. This dimensionality gap caused inference panics due to missing inputs and unmapped numerical structures (e.g., standard Age vs. Categorical Age buckets).
[ MITIGATION_PROTOCOL ]
- PREPROCESSING_SERVICE_INJECTION: Architected a robust middleware Translation Layer between the API gateway and the Inference Engine.
- DATA_IMPUTATION_AND_MAPPING: The layer automatically calculates clinical BMI from user metric inputs (kg/cm), maps chronological Age using a custom dictionary lookup to the internal categorical scale, and injects statistically representative “neutral” constants for unasked socio-economic features (Education, Income).
- THRESHOLD_ADJUSTMENT: Recalibrated the model to a custom
0.3risk threshold to maintain high sensitivity despite the imputed data.
RESULT: The application successfully bridges the gap between a consumer-friendly 17-question UI and a rigid 21-feature clinical model, maintaining rapid inference and high sensitivity without burdening the user with invasive questions.